코틀린 시퀀스(Sequence)를 이용한 지연 연산에 대해 알아보자
많은 데이터를 다룰때 컬렉션 함수의 비효율성
코틀린은 표준 라이브러리를 통해 filter, map 와 같은 컬렉션 연산을 수행하는 함수를 지원하여, 편의를 제공합니다.
이러한, 컬렉션 함수는 즉시 연산을 수행합니다. 예를 들어, filter와 map과 같은 경우는 연산 결과로 리스트를 반환하므로, 컬렉션 함수가 연쇄적으로 수행될 때, 매 단계마다 중간 결과를 새로운 컬렉션에 임시로 담게 됩니다. 만약 컬렉션의 원소가 많다면, 이는 연산의 효율이 떨어지는 결과를 초래합니다.
이때, 시퀀스(Sequence)를 이용하면 중간 결과를 임시로 컬렉션에 담지 않고 연산을 연쇄적으로 수행하여 효율성을 높일 수 있습니다.
시퀀스란?
시퀀스는 Sequence 인터페이스를 통해 수행됩니다. 해당 인터페이스는 한 번에 하나씩 열거될 수 있는 원소의 시퀀스를 표현하는 역할을 하며, iterator 메서드를 통해 시퀀스로부터 원소 값을 얻을 수 있습니다.
시퀀스를 통해 컬렉션 연산을 연쇄적으로 수행할 때, 중간 결과를 저장하기 위한 임시 컬렉션이 생기지 않기 때문에 많은 데이터의 연산을 수행한다면 효과적일 수 있습니다.
이러한 특징은 원소를 필요할 때 계산하는 지연(lazy) 연산에 있습니다.
시퀀스 사용 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Test
fun sequenceTest() {
val people = listOf(
Person(name = "주드", age = 27),
Person(name = "홀길동", age = 25)
)
val result = people.asSequence() // 컬렉션을 시퀀스로 변환
.filter { it.age > 26 }
.map { it.name }
.toList() // 다시 시퀀스를 컬렉션으로 변환
println(result)
}
asSequence를 통해 리스트인 컬렉션을 시퀀스로 변환합니다.filter,map에서 볼 수 있듯, 시퀀스도 컬렉션과 같은 컬렉션 함수 연산을 제공합니다.toList를 통해 다시 시퀀스를 리스트 컬렉션으로 변환합니다.
중간 연산과 최종 연산
지연 연산에 대해 알아보기 전, 시퀀스 연산의 종류에 대해 먼저 알아보겠습니다.
시퀀스 연산은 중간 연산과 최종 연산으로 구분할 수 있습니다.
중간 연산
중간 연산은 연산 결과로 시퀀스를 반환합니다.
- ex)
map,filter…
최종 연산
최종 연산은 결과를 반환합니다. 여기서 말하는 결과는 시퀀스로부터 계산을 통해 얻을 수 있는 컬렉션, 원소, 숫자, 객체가 될 수 있습니다.
- ex)
toList,sum…
즉, 지연 연산이란 중간 연산은 최종 연산이 수행되는 시점까지 계속 지연되는 것을 의미합니다. 다시 말해, 최종 연산이 없다면, 중간 연산을 수행되지 않게 되며, 최종 연산이 호출되어야 비로소 중간 연산들이 수행되는 것을 의미합니다.
다음 예제 코드를 통해 정말 그런지 확인해 보겠습니다.
최종 연산이 없을 때 중간 연산 수행 X
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Test
fun lazyTest1() {
val numbers = listOf(1,2,3)
numbers.asSequence()
.filter {
println("filter number: $it")
it > 2
}
.map {
println("map number: $it")
it * it
}
}
- 아무 내용도 출력되지 않습니다.
최종 연산이 있을 때 중간 연산 수행 O
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Test
fun lazyTest2() {
val numbers = listOf(1,2,3)
numbers.asSequence() // 컬렉션을 시퀀스로 변환
.filter {
println("filter number: $it")
it > 2
}
.map {
println("map number: $it")
it * it
}
.toList()
}
- 최종 연산인,
toList가 수행되므로, 중간 연산이 수행됩니다. 출력 결과
1 2 3 4
filter number: 1 filter number: 2 filter number: 3 map number: 3
시퀀스 연산의 수행 순서
연쇄적으로 컬렉션 연산을 수행할 때, 컬렉션에 대한 연산과 시퀀스에 대한 연산은 수행 순서에 차이가 존재합니다.
컬렉션의 연산 수행 순서
1
2
3
4
5
6
7
8
9
10
@Test
fun collectionOrderTest() {
val numbers = listOf(1, 2, 3)
val result = numbers
.map { it * it }
.filter { it > 3 }
println(result)
}
- 모든 원소[1, 2, 3]에 대해
map함수를 모두 수행하여 중간 결과값[1, 4, 9] 생성 - 중간 결과값에 대해
filter함수를 수행
→ 결과 [4, 9]
시퀀스의 연산 수행 순서
1
2
3
4
5
6
7
8
9
10
11
12
@Test
fun sequenceOrderTest() {
val numbers = listOf(1, 2, 3)
val result = numbers
.asSequence()
.map { it * it }
.filter { it > 3 }
.toList()
println(result)
}
각 원소에 대해 순차적으로 연산을 수행합니다.
- 첫 번째 원소가
map연산 수행 후,filter연산을 수행 - 두 번째 원소가
map연산 수행 후,filter연산을 수행 - 세 번째 원소가
map연산 수행 후,filter연산을 수행
→ 결과 [4, 9]
이러한 시퀀스 연산 수행 순서의 특징을 통해 남은 원소에 대해 연산이 수행되기 전에 결과가 먼저 얻어지면, 남은 원소에 대해서는 연산이 이루어지지 않을 수 있습니다.
시퀀스의 연산 수행 특징으로 인해 변환 연산이 이루어지지 않는 원소가 발생
1
2
3
4
5
6
7
8
9
10
11
@Test
fun orderTest() {
val numbers = listOf(1,2,3)
numbers.asSequence()
.map {
println("map number: $it")
it * it
}
.find { it > 3 }
}
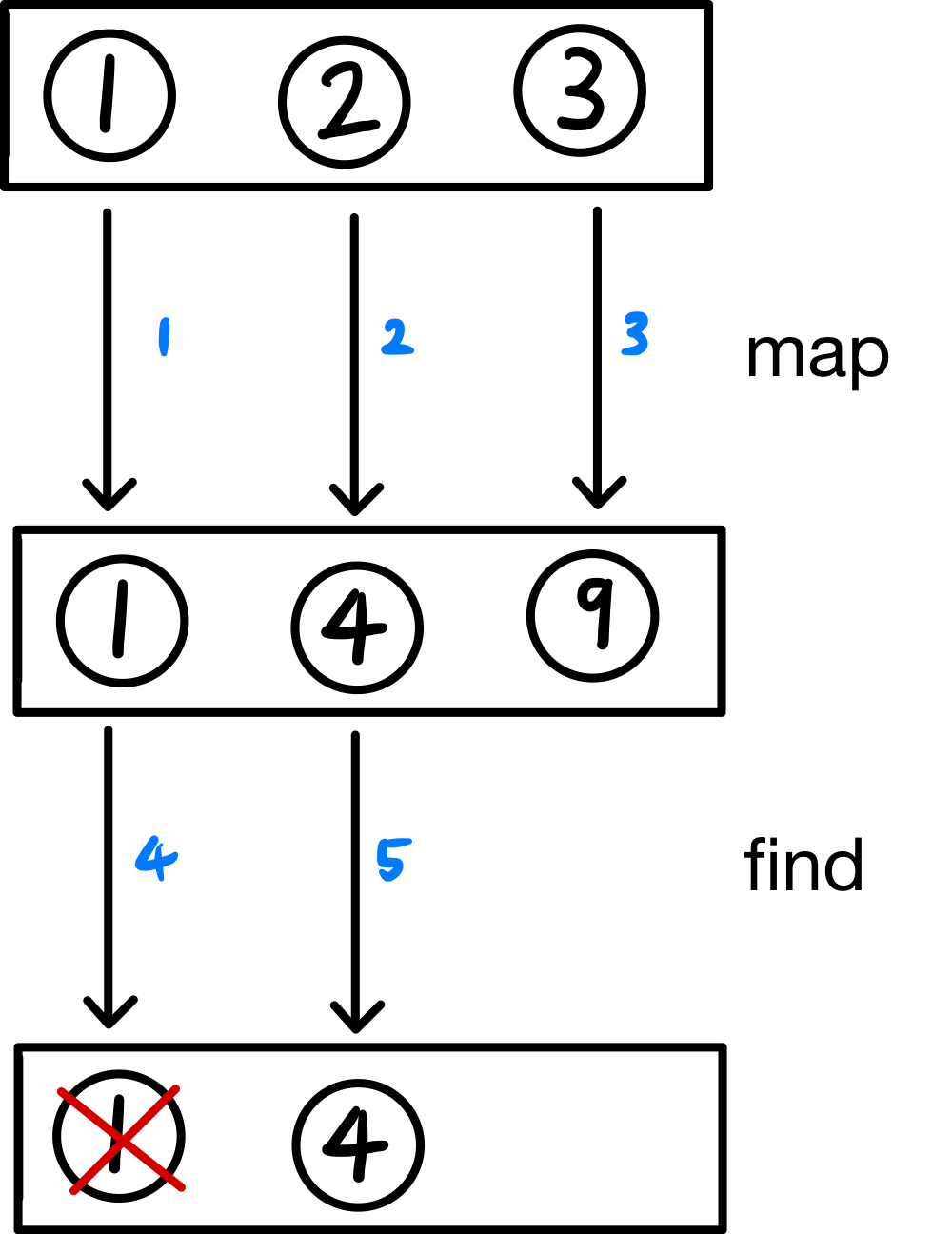
map을 통해 각 원소의 숫자를 제곱하고, find를 통해 제곱한 값이 3보다 큰 첫 번째 원소를 찾습니다.
출력 결과
1 2
map number: 1 map number: 2
원소 2에 대해 제곱을 수행한 결과가 4이므로, 제곱의 결과가 3보다 큰 원소를 find를 통해 찾았습니다.
여기서 주목해야 될 시퀀스 연산(지연 연산)의 특징은, 남은 원소 3에 대해 연산을 수행되기 전, 이미 답을 찾았으므로 원소 3에 대해서는 제곱을 수행하는 map 연산이 수행되지 않았다는 것입니다.
즉시 연산(컬렉션 연산)
지연 연산(시퀀스 연산)
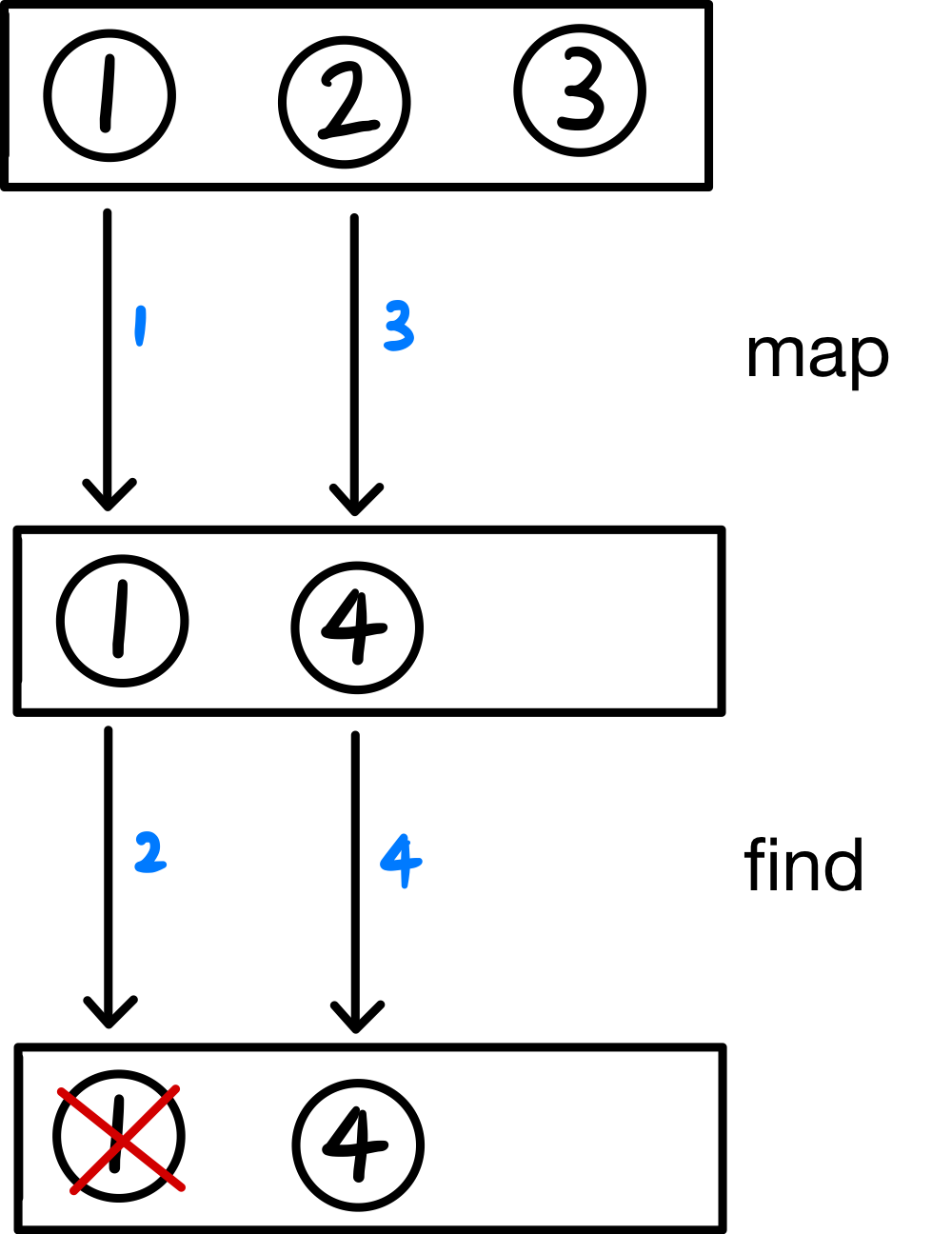
이러한 연산 순서의 특징으로 인해, 연산의 순서도 성능에 영향을 줄 수 있습니다.
예를 들어 사람들 중 나이가 30 이상인 사람들의 나이를 얻는다고 가정해 보겠습니다.
filter를 이용해 나이가 30 이상인 사람들을 찾을 수 있다map을 이용해 나이를 추출할 수 있다
filter와 map은 어떤 순서로 연산이 이루어지더라도 같은 결과를 얻을 수 있습니다. 하지만, 연산의 수행 횟수는 연산 순서에 따라 다를 수 있습니다.
map 연산을 통해 나이의 값을 원소로 변환한 뒤, filter를 통해 30 이상인 나이를 필터링
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
@Test fun orderTest1() { val people = listOf( Person(name = "주드", age = 27), Person(name = "홀길동", age = 30), Person(name = "김길동", age = 31) ) var calcCount = 0 val result = people.asSequence() .map { calcCount++ it.age } .filter { calcCount++ it >= 30 } .toList() println("총 연산 횟수: $calcCount") println("연산 결과: $result") }
출력 결과
1 2
총 연산 횟수: 6 연산 결과: [30, 31]
filter를 통해 30 이상인 나이를 필터링한 뒤, map 연산을 통해 나이의 값을 원소로 변환
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
@Test fun orderTest2() { val people = listOf( Person(name = "주드", age = 27), Person(name = "홀길동", age = 30), Person(name = "김길동", age = 31) ) var calcCount = 0 val result = people.asSequence() .filter { calcCount++ it.age >= 30 } .map { calcCount++ it.age } .toList() println("총 연산 횟수: $calcCount") println("연산 결과: $result") }
출력 결과
1 2
총 연산 횟수: 5 연산 결과: [30, 31]
연산의 결과는 같으나, 총 연산 횟수가 다른 것을 확인할 수 있습니다.
자바의 스트림과 코틀린의 시퀀스
코틀린의 시퀀스는 자바의 스트림(Stream)과 같은 개념입니다. 그럼에도 불구하고, 코틀린에서 시퀀스를 따로 구현하여 제공하는 이유는 스트림이 생기기 전인 Java8 이전 버전을 사용하는 경우에는 스트림이 없기 때문입니다.
다만, 스트림을 사용할 수 있는 Java8 이상의 버전을 사용한다면 시퀀스와 달리, 스트림을 이용하여 쉽게 병렬 연산(ParallelStream)을 수행할 수 있다는 특징이 있습니다. (하지만 병렬 연산은 오버헤드가 발생하기 때문에, 항상 좋다고 판단할 수는 없습니다)
시퀀스가 항상 효과적일까?
지금까지 시퀀스를 이용한 여러 특징들을 알아봤습니다. 그럼 모든 컬렉션 연산에 대해서 시퀀스를 적용하는 게 효과적일까요?
결론부터 말씀드리면 항상 그런 건 아닙니다.
컬렉션 함수는 인라인 함수이므로, 시퀀스를 사용하지 않은 컬렉션 함수 호출 시 람다가 인라이닝 되는 반면, 시퀀스 연산에서는 람다가 인라이닝 되지 않습니다.
즉, 원소가 충분히 많지 않아 크기가 작은 컬렉션에 대해서는 오히려 시퀀스 연산이 더 성능이 좋지 않을 수 있습니다.
람다의 인라이닝이란?
inline 키워드가 함수에 붙으면, 해당 함수를 호출하는 곳에 함수 본문에 해당하는 바이트코드로 컴파일 됩니다. 즉, 함수의 본문이 인라인 됩니다.
→ 이를 통해 람다로 인해 발생하는 무명 클래스 생성 부가비용을 없애줍니다.
Dmitry Jemerov, Svetlana Isakova, ⌜Kotlin In Action⌟, 오현석 옮김, 에이콘출판사, 2017, p.223-227