적절한 로컬 캐시 사용을 고려하자
캐시란?
캐시는 데이터를 빠르게 접근할 수 있는 고속 저장소로서, 자주 사용되거나 조회가 많은 데이터를 캐시에 저장하면, 데이터베이스를 직접 조회하는 것보다 훨씬 빠르게 데이터를 가져올 수 있습니다.
이를 통해 성능을 향상시키고, 요청에 대한 응답 시간을 최적화할 수 있습니다.
로컬 캐시 vs 글로벌 캐시
캐시는 크게 데이터 저장 위치에 따라, 외부 캐시 서버에 데이터를 저장하는 글로벌 캐시와 각 서버 메모리에 데이터를 저장하는 로컬 캐시로 구분할 수 있습니다.
글로벌 캐시
글로벌 캐시는 별도의 캐시 서버를 두고 데이터를 저장하는 방식입니다.
- ex) Redis, Memcached

장점
- 여러 서버가 동일한 데이터를 조회할 수 있어 데이터 일관성 유지가 용이합니다.
- 별도의 캐시 서버를 사용하므로, 메모리 사용이 효율적이며 데이터 중복 저장 문제를 줄일 수 있습니다.
단점
- 일반적으로 DB 조회보다는 빠르지만, 로컬 캐시에 비해 네트워크 통신 지연이 발생합니다.
- 별도의 캐시 서버를 구축하고 운영해야 하므로 추가적인 인프라 관리 비용이 발생합니다.
- 캐시 서버에 의존적으로, 만약 캐시 서버가 장애를 일으키면 전체 시스템에 영향을 미칠 수 있습니다. (단일 실패 지점, SPOF)
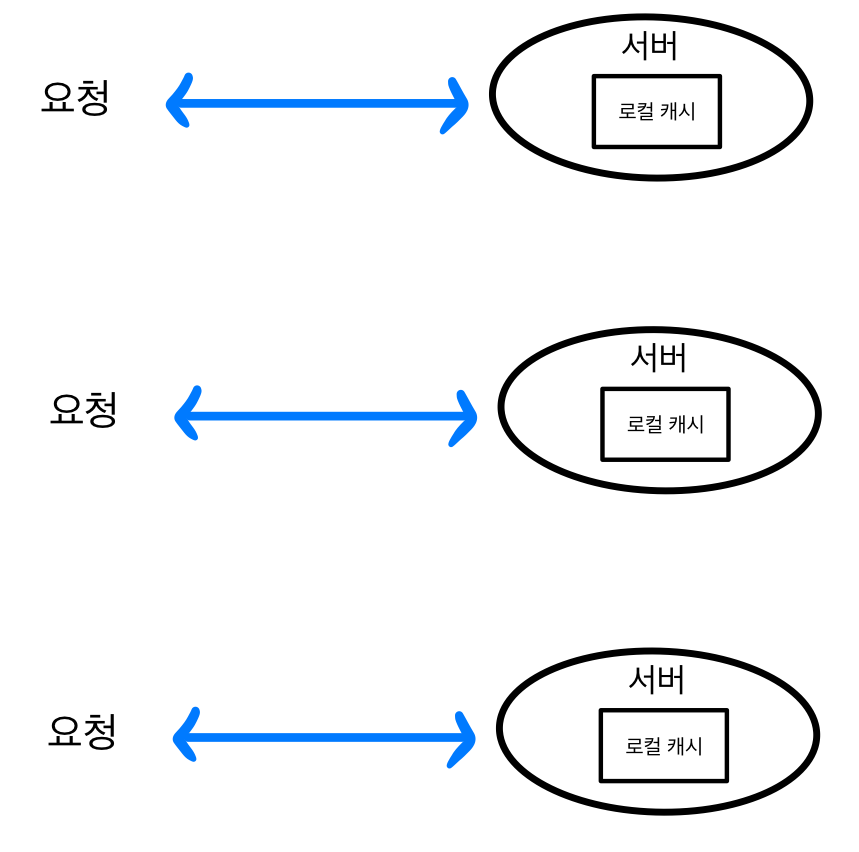
로컬 캐시
로컬 캐시는 각 서버의 메모리에 데이터를 저장하여 사용하는 방식입니다.
- ex) ConcurrentHashMap, Ehcache, Caffeine
장점
- 네트워크 통신 없이 메모리에서 직접 조회하므로 지연 없이 매우 빠른 응답이 가능합니다.
- 외부 인프라를 사용하지 않아 리소스 비용이 줄어들고, 외부 시스템에 대한 의존도가 낮아집니다.
단점
- 분산 환경에서는 서버 간 데이터가 달라질 수 있어 데이터 일관성 유지가 어렵습니다.
- 서버마다 데이터가 중복 저장되어 전체 메모리 사용량이 늘어날 수 있습니다.
- 메모리에 저장하는 구조이므로, 캐시 크기가 Heap 메모리 용량에 제약을 받습니다. 데이터가 과도하게 쌓이면 OOM(Out of Memory)가 발생할 수 있습니다.
일반적으로 글로벌 캐시를 먼저 떠올리는 이유
대부분 캐시에 대해 이야기할 때, 글로벌 캐시 시스템(ex Redis, Memcached)을 먼저 떠올립니다.
이는 최근 서비스들이 고가용성을 위해 스케일 아웃을 통해 여러 서버를 운영하는 경우가 많기 때문입니다.
로컬 캐시를 사용할 경우 서버 간 캐시를 각각 가지고 있어, 캐시 데이터 불일치(정합성 문제)가 발생할 수 있지만, 글로벌 캐시를 사용하면 서버 간 캐시 데이터를 공유하게 되어 각 서버가 최신 데이터를 사용하게 됩니다.
이로 인해 정합성 문제가 발생하지 않아, 글로벌 캐시가 선호되는 경향이 있습니다.
그렇다면 로컬 캐시는 언제 사용할까?
하지만 서비스 특성과 요구사항에 따라 로컬 캐시와 글로벌 캐시를 적절히 조합해서 사용하는 것이 중요합니다.
다음과 같은 경우에는 로컬 캐시를 사용하는 것이 더 효율적일 수 있습니다.
- 캐시할 데이터 양이 적어 글로벌 캐시를 사용하는 것이 오히려 비효율적일 때
- 캐시해야 할 데이터 양이 적다면, 서버의 메모리에 데이터를 저장해도 메모리 사용량 부담이 크지 않습니다.
- 이 경우에도 글로벌 캐시를 사용하면 오히려 네트워크 통신 지연, 외부 인프라 장애 리스크, 추가적인 운영 및 비용 부담이 생길 수 있습니다.
- 따라서 데이터 양이 작다면, 로컬 캐시가 더 효율적인 선택이 될 수 있습니다.
- 변경이 드물지만 조회가 빈번한 데이터가 있을 때
- 예를 들어, 시스템 설정 값처럼 자주 변경되지 않는 데이터는 글로벌 캐시나 DB를 매번 조회하기보다는 로컬 캐시에 저장해 두고 빠르게 읽는 것이 성능 최적화에 도움이 됩니다.
- 최종적 일관성(Eventual Consistency)을 허용할 수 있을 때
- 최종적 일관성은 모든 분산 서버가 즉각적으로 동일해질 필요는 없지만, 일정 시간이 지난 후에는 결국 일관된 상태로 수렴하는 특성을 의미합니다.
- 로컬 캐시는 서버별로 데이터를 유지하기 때문에, 업데이트 시점에 따라 서버 간 데이터가 일시적으로 달라질 수 있습니다.
- 즉, 일시적인 데이터 불일치가 허용된다면 로컬 캐시를 고려할 수 있습니다.
- 2계층 캐시 구조(로컬 캐시 → 글로벌 캐시 → DB)를 구성할 때
- 이 구조는 읽기 성능 최적화와 일관성 유지를 모두 고려할 때 유용합니다.
- 요청 시 먼저 로컬 캐시를 조회하고, 없으면 글로벌 캐시를 조회하며, 글로벌 캐시에도 없을 경우 최종적으로 DB를 조회합니다.
- 이렇게 하면 DB 부하를 줄이면서, 글로벌 캐시와 로컬 캐시를 효율적으로 사용할 수 있습니다.
로컬 캐시를 사용하는 예시 상황
다음과 같은 예시 상황을 들어, 로컬 캐시 라이브러리인 Caffeine을 사용한 코드 예시를 확인해 보겠습니다.
자주 변경되지는 않지만, 특정 카테고리 ID 기준으로 하위 카테고리 목록을 자주 조회하는 상황에서, 매번 DB를 조회하지 않고 로컬 캐시를 활용하여 성능을 최적화하는 상황
build.gradle 의존성 추가
1
2
3
4
dependencies {
implementation("org.springframework.boot:spring-boot-starter-cache")
implementation("com.github.ben-manes.caffeine:caffeine")
}
- Spring Cache와 Caffeine 의존성을 추가합니다.
캐시 설정 클래스
Spring Boot에서 Caffeine을 로컬 캐시로 사용할 수 있도록 설정합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Configuration
@EnableCaching
class CacheConfig {
@Bean
fun cacheManager(): CacheManager {
val caffeineBuilder = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES) // 캐시 유효기간 10분
.maximumSize(1000) // 최대 1000개 항목 저장
val cacheManager = CaffeineCacheManager("childCategories") // 캐시 이름을 childCategories로 설정
cacheManager.setCaffeine(caffeineBuilder)
return cacheManager
}
}
@EnableCaching- Spring의 캐시 기능을 활성화 합니다.
expireAfterWrite(10, TimeUnit.MINUTES)- 캐시 데이터의 유효기간을 10분으로 설정합니다.
maximumSize(1000)- 최대 1000개까지만 저장하고 초과 시 LRU 기반으로 제거합니다.
CaffeineCacheManager("childCategories")- 이름이 “childCategories”인 캐시를 등록합니다.
서비스 계층에 캐시 적용
카테고리 ID를 기준으로 하위 카테고리 목록을 조회하고, 결과를 캐시합니다.
1
2
3
4
5
6
7
8
9
@Service
class CategoryService(
private val categoryRepository: CategoryRepository
) {
@Cacheable(value = ["childCategories"], key = "#parentCategoryId")
fun getChildCategories(parentCategoryId: Long): List<Category> {
return categoryRepository.findByParentId(parentCategoryId)
}
}
@Cacheable를 통해 캐시를 적용합니다.value = ["childCategories"]: 사용할 캐시 이름 지정key = "#parentCategoryId": 파라미터parentCategoryId값을 캐시 키로 지정
- 같은 ID로 재호출할 경우 캐시된 하위 카테고리 목록을 반환하여 DB 부하를 줄입니다
테스트 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Test
fun `같은 상위 카테고리 ID로 하위 카테고리 목록 연속 조회시 DB 조회는 한번만 호출된다`() {
// given
val parentId = 1L
// when
val firstCall = categoryService.getChildCategories(parentId)
val secondCall = categoryService.getChildCategories(parentId)
// then
// 결과는 같아야 한다
assertThat(firstCall).isEqualTo(secondCall)
// DB를 조회하는 Repository 계층의 findByParentId 메서드는 단 한번만 호출되어야 한다
verify(categoryRepository, times(1)).findByParentId(parentId)
}
- 첫 번째 호출 시, DB에서 하위 카테고리 목록을 조회합니다.
- 두 번째 호출 시, 캐시에 저장된 데이터가 있으므로 DB 조회 없이 캐시에서 데이터를 반환합니다.
테스트 결과

로컬 캐시 동기화를 위한 메시징 시스템
앞서 로컬 캐시의 단점으로, 분산 환경에서는 서버 간 캐시 데이터가 달라질 수 있어 데이터 불일치로 인한 정합성 문제가 발생할 수 있다고 언급했습니다. 즉, 로컬 캐시는 서버 간 데이터를 공유하지 않기 때문에, 하나의 서버에서 데이터가 갱신되더라도 다른 서버의 캐시에는 반영되지 않는 문제가 있습니다.
그렇다면 로컬 캐시에서는 정합성 문제를 해소할 방법이 전혀 없는 것일까요?
이를 해결하기 위해 Kafka, Redis Pub/Sub와 같은 메시징 시스템을 활용하여 로컬 캐시 동기화를 구현할 수 있습니다. 이는 어떤 서버에서 특정 데이터가 업데이트되었을 때, 해당 이벤트를 메시지로 발행하고, 이를 구독 중인 다른 서버들이 메시지를 수신하면 해당 키에 대한 캐시를 갱신하거나 삭제하는 방식입니다.
이러한 구조를 사용하면, 로컬 캐시를 사용하면서도 데이터 변경 사항을 실시간에 가깝게 다른 서버들에 전파할 수 있어, 데이터 정합성 문제를 어느 정도 완화할 수 있습니다.
정리
- 로컬 캐시를 사용하면 네트워크 통신 없이 빠르게 데이터를 조회할 수 있으나, 분산 환경에서 데이터 정합성 문제가 발생할 수 있습니다.
- 글로벌 캐시는 여러 서버 간 데이터 일관성을 보장하지만, 네트워크 지연과 외부 인프라에 의존적입니다.
- 로컬 캐시를 사용하더라도 메시징 시스템을 활용하면 데이터 정합성 문제를 완화할 수 있습니다.
- 서비스 특성과 데이터 특성에 따라 로컬 캐시와 글로벌 캐시를 적절히 조합하여 사용하는 것이 중요합니다.
카카오페이 기술 블로그, “분산 시스템에서 로컬 캐시 활용하기”, https://tech.kakaopay.com/post/local-caching-in-distributed-systems/, (참고 날짜 2025.04.27)
티스토리, “로컬캐시 이해하기! (feat. 글로벌 캐시)”, https://jaehoney.tistory.com/438, (참고 날짜 2025.04.27)
티스토리, “[Spring] 로컬 캐시(Local Cache) 도입으로 성능 개선하기”, https://developer-nyong.tistory.com/78, (참고 날짜 2025.04.27)